.webp)

.webp)
.webp)
.webp)
.webp)
.webp)













.webp)



.webp)
What an AI-Ready Salesforce Org Looks Like (and How to Get There)
AI for Salesforce is suddenly everywhere. From conversational copilots in the UI to Agentforce agents and generative features showing up in almost every new release.
But there is an uncomfortable truth most teams are bumping into:
If your Salesforce org is a mess, AI will just scale the mess.
In our recent webinar "What an AI-Ready Salesforce Org Looks Like", Kevin Magyar walked through what he has seen across hundreds of orgs and what actually separates AI-ready orgs from everyone else. This article distills that conversation into a practical roadmap you can steal.
Why AI Has Made Org Health Non-Negotiable
Org health has always mattered but AI has really turned it into a "must-have."
A few realities collide:
-
Less hand-holding. Stakeholders increasingly interact with AI copilots and agents directly, without going through the Salesforce team first.
-
Higher deployment velocity. The business expects more automation, faster iteration and cross-system workflows that lean on Salesforce as a source of truth.
-
Tech debt does not disappear. It gets amplified. Misnamed fields, duplicate objects, legacy automations: AI will consume all of it unless you deliberately constrain and document what you want it to see.
Historically, org-health initiatives were triggered by things like a new Salesforce owner coming in, large acquisitions or migrations. Now, we're seeing AI as the big catalyst for org-health prioritization.
The AI Readiness Roadmap for Salesforce
AI-readiness should not be a vague aspiration or a feature checklist. It is a progression of concrete org-health tasks.
A practical Salesforce AI readiness roadmap looks something like this:
-
Document and map your data
Capture key data models and build a data dictionary. -
Classify data
Label PII, confidential and other sensitive data using Salesforce metadata tools. -
Review data security and access controls
Tighten field-level security, sharing rules and encryption. -
Ensure data quality and cleanup
Fix duplicates, normalize values and reduce noise. -
Align AI agents with business processes
Map AI capabilities to real workflows, not just "cool features". -
Set up and govern prompts
Standardize and manage prompts with clear ownership and change control. -
Compliance, auditing and risk management
Ensure auditable logs and fallback paths for AI actions. -
Change management and training
Prepare users for AI in their day-to-day work. -
Test, monitor, improve
Pilot agents, monitor outcomes and iterate continuously.
We will unpack the most important pieces of that roadmap below especially the ones that surfaced again and again in our customer stories.
Phase 1: Document and Map Your Data
The first question in any AI-readiness journey is brutally simple:
"Do you actually know what is in your org?"
For most teams, the honest answer is "not really" due to:
-
Years of incremental customization
-
Multiple consultants and internal owners "burying bodies" in automation and custom fields
-
Little to no consistent documentation of what fields are for, how they are used, or which teams rely on them
That is why the roadmap starts with documenting your current state:
-
Are the fields you are actually using properly documented?
-
Do they have help text and descriptions with the kind of context an LLM needs to deliver useful results?
-
Are you eliminating anything that would confuse AI: duplicate values, ambiguous names, dead-end fields?
This is where a Salesforce data dictionary becomes foundational, not optional.
The data dictionary as the foundation of AI context
A good data dictionary sits on top of your metadata and describes how you are using Salesforce:
-
Objects and fields
-
How those fields are populated and by whom
-
Which teams rely on them
-
How sensitive they are
-
What they actually mean in business language
From a practical standpoint, a data dictionary should help you:
-
Add business context to technical components
Translate cryptic API names into definitions humans and AI can use. -
Share a dynamic dictionary across teams
So admins, ops, finance, sales and data science are literally using the same words. -
Quickly add compliance categories
Mark which fields are PII, confidential or otherwise sensitive, so they can be treated differently by AI and integrations.
The biggest mindset shift: a data dictionary is no longer just a reference spreadsheet for admins. It is a strategic, cross-department asset that underpins collaboration and shared understanding across the business.
The Horror Story: 16 "Billing State" Fields
One real customer example from the webinar captures the stakes perfectly.
When they took stock of their org, they discovered:
16 different fields that referenced "billing state".
Their admin kept being asked by teams like Finance and Data Science asking, "Which field(s) is the right one?"
At human speed, that is annoying but survivable. At AI speed, it is catastrophic:
-
Which "billing state" does AI pick?
-
What happens when dashboards, forecasts or AI-generated insights use inconsistent definitions?
-
How quickly does trust evaporate when numbers do not line up between teams?
The same org also had multiple "revenue" fields with slightly different meanings (one-time, recurring, IRR and so on). AI cannot magically infer which one you meant.
This is why "clean foundation first" kept coming up. If you do not know what you have, it is hard to assign value, feed AI the right context, or even align internal stakeholders on which fields matter.
Phase 2: Classify and Protect Sensitive Data
Once you understand your data model and core fields, the next step is to classify data by sensitivity.
Most Salesforce orgs contain highly sensitive information spread across objects and fields:
-
Personal identifiers
-
Health or financial data
-
Contract terms
-
Internal-only notes and risk flags
You do not want all of that exposed to AI models by default.
A simple but powerful pattern:
-
Identify sensitive fields, automation and reports
Inventory where sensitive data lives across objects and metadata. -
Tag and classify those assets
Use field-level metadata or a data dictionary layer to label PII, confidential, internal-only and so on. -
Fence off access
-
Keep those fields out of AI context windows entirely, or
-
Enforce strict guardrails around when and how they are referenced.
-
Done well, classification gives you:
-
A clear line between "safe for AI" and "never expose to AI"
-
A foundation for policy enforcement, access reviews and downstream compliance work
-
A shared language between security, legal and Salesforce teams
The work is not conceptually complicated. At scale, it becomes very hard without automation and a central dictionary.
Phase 3: Fix Data Quality and Close the Loops
Even if fields are well-documented and properly classified, you still need to ask:
"Is this data any good?"
Two roadmap items are key here:
-
Ensure data quality and cleanup
Fix duplicates, normalize formats, deprecate dead fields. -
Review data security and access controls
Audit field-level security, sharing rules and encryption.
In practice, that means:
-
Finding fields that are populated with the wrong information
-
Finding fields that are never populated at all (and can be deprecated or excluded from AI)
-
Removing slightly different versions of the same concept ("revenue", "ARR", "booked revenue") that confuse reporting and AI outputs
Many "AI risks" are actually process problems, not purely technical ones:
-
Loopholes in how data is entered or updated
-
Inconsistent workflows between teams
-
Lack of alignment on which process is the source of truth for a particular metric
Cleaning data quality and tightening processes is not glamorous, but it is the difference between AI that people trust and AI that just adds noise.
Phase 4: Align AI Agents With Real Business Processes
Another common failure mode is treating AI as something you "turn on" rather than something you design around real work.
Instead of asking, "What can AI do in Salesforce?", better teams ask: "Where in this process do humans struggle today, and can AI help with context, suggestions or automation safely?"
Successful AI projects:
-
Start with a specific workflow:
Example: lead qualification, case triage, forecast reviews, renewal risk analysis. -
Use documented, trusted fields:
They lean on the parts of the data model that have already been cleaned and defined. -
Have clear guardrails:
Define which updates AI is allowed to make, which it can only suggest, and when a human must approve.
When you align AI agents with processes, you get concrete outcomes: faster case handling, better data entry, more consistent follow-up. When you do not, you just get demos.
Phase 5: Governance, Observability and Continuous Improvement
Once AI agents are active, you need to see what they are doing and prove you are in control.
That means:
-
Prompt governance
Store prompts centrally. Control who can change them. Version them. Review them. -
Compliance, auditing and risk management
Log what AI read, what it did and how it interacted with Salesforce. Have clear rollback and override paths. -
Testing, monitoring and improvement
Start with pilots. Monitor quality, edge cases and adoption. Iterate prompts, policies and data model changes.
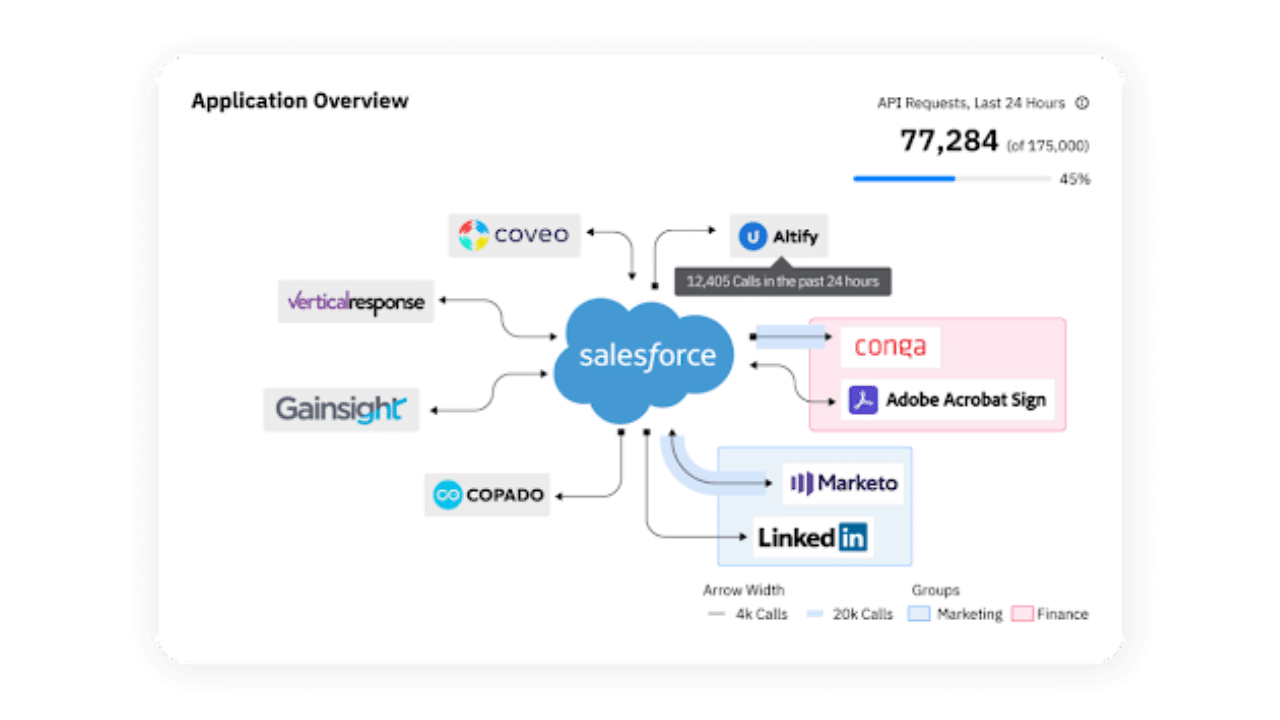
For Salesforce specifically, this should sit on top of a broader observability layer that gives you:
-
Real-time visibility into new applications and integrations touching Salesforce
-
Monitoring of API usage and limits, so you know which systems are driving what load
-
Alerts on unusual access patterns or behavior that might signal misuse, bugs or attacks
Together with the data dictionary, observability creates both context and control:
-
Context so AI can pick the right fields and reports
-
Control so AI and integrations cannot go places they should not, or act without an audit trail
How to Start Without Getting Overwhelmed
Everyone loves the roadmap until they remember how many objects and fields are in their org.
The way out is to start very small and very focused.
A practical pattern that comes up again and again:
-
Pick one object (for example Opportunity or Case).
-
Focus on 10 to 20 of the most referenced or highly populated fields.
-
Decide what documentation and context actually matter: meaning, owner, source system, sensitivity, usage notes.
-
Get that slice clean and documented.
-
Then reuse that structure for the next object.
Why this works:
-
You get fast, visible success you can point to internally.
-
You prove the business value of a data dictionary: fewer questions, fewer mistakes, better reports.
-
You learn how you want to operationalize documentation long-term, instead of trying to design everything up front.
In some teams, especially in complex environments like education or financial services, this first documented object becomes the basis for a shared language between frontline users, finance and data science.
Rethinking What a Data Dictionary Is
If there is one mindset shift to take away, it is this:
A data dictionary is no longer just an admin tool. It is a strategic asset for AI readiness and cross-team collaboration.
When you treat it that way:
-
You stop documenting fields only when something breaks.
-
You start using the dictionary to drive design reviews, intake processes and change management.
-
You give security, legal and compliance teams a concrete artifact to engage with, instead of abstract worries about "AI risk".
-
You give AI agents a clean, well-lit playground instead of a junkyard.
At that point, AI-readiness is not a separate project. It is the natural outcome of running a healthy Salesforce org.
Key Takeaways: What an AI-Ready Salesforce Org Really Looks Like
If you want the short version, here it is:
-
AI-ready = healthy org. You cannot skip org health and expect AI to compensate. It will amplify whatever state your org is already in.
-
Start with visibility. Build a data dictionary that documents fields, usage and sensitivity - and share it across teams.
-
Clean up before you plug in AI. Remove duplicate and ambiguous fields, unify critical concepts like "billing state" and "revenue", standardize naming and usage.
-
Classify and protect sensitive data. Know exactly which fields AI should never touch and enforce that with metadata, security and observability.
-
Treat AI as part of the business process, not a toy. Align agents with real workflows and give them clear guardrails and auditability.
-
Start small, then scale. One object, 10 to 20 fields, a handful of key stakeholders - and build from there.